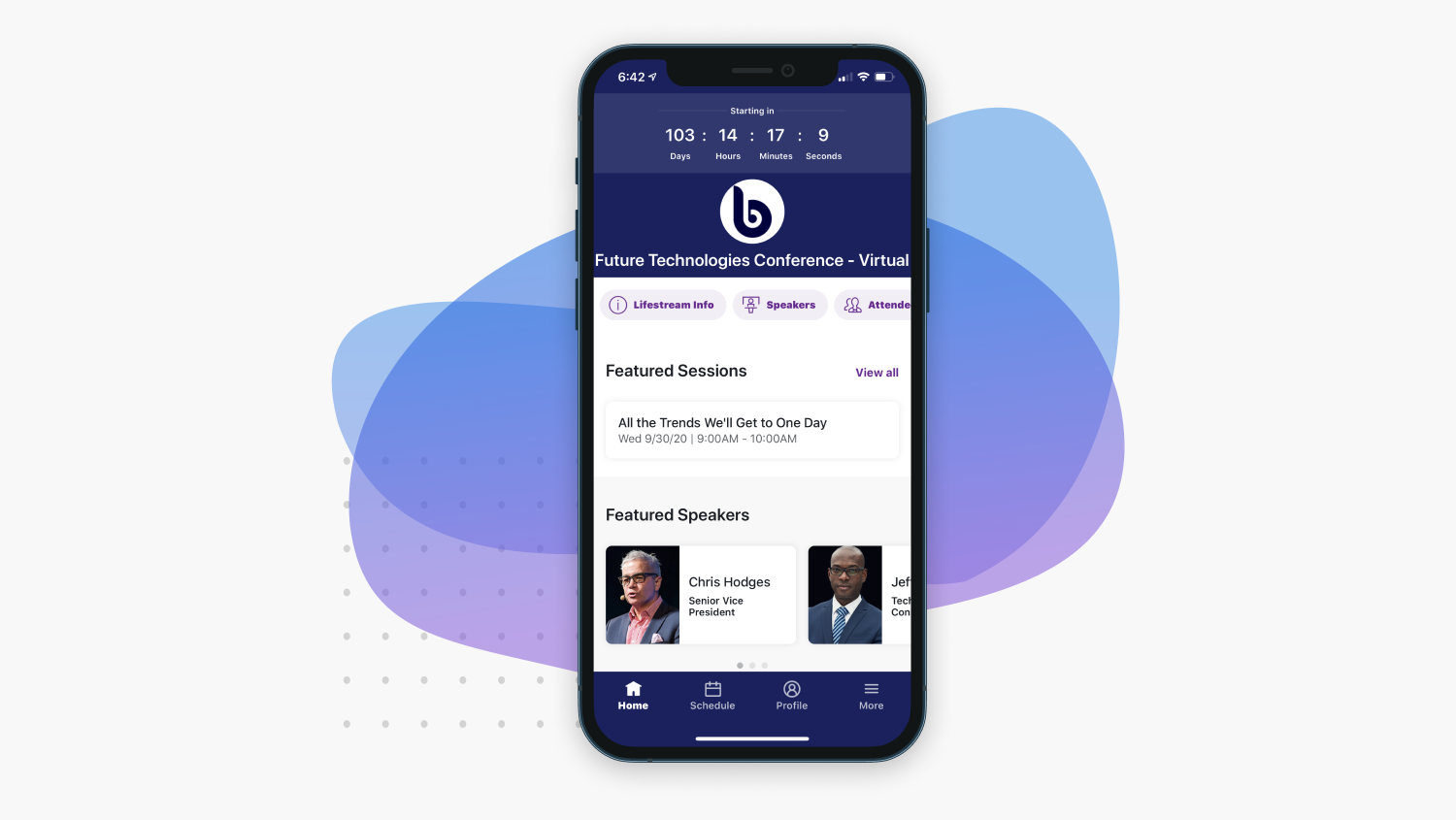
Event apps that make it easier than ever to interact and engage with your attendees








Rethink how attendees interact with your event app
Fully integrated within the Cvent platform to bring digital engagement and connectivity to the next level.





Hear what our customers have to say

InXpress
InXpress used Cvent’s integrated solutions to host a safe hybrid event, generating over 150 mobile app downloads, 1.5K check-ins, and dozens of 1:1 appointments.
- 1,500 check-ins virtually and onsite
- 165+ app downloads
- $45K in sponsorship revenue

GBA
With the help of Cvent technology, GBA was able to automate labor-intensive tasks and create a more consistent member experience across the attendee journey.
-
50% app adoption rate
-
81 sessions managed
-
800+ registrants

YPO
YPO leveraged the Cvent Mobile Event App to meet the immediate networking needs of their members, and create a sense of connectivity and community.
-
300,000 global registrations
-
6,000+ annual events
-
5,000+ virtual attendees
Further enhance Cvent Attendee Hub with:




Common Questions
Mobile event apps are an application designed to be installed on modern smartphones. They serve to help attendees navigate an event by providing important information such as agendas, maps, session information, attendee profiles and more. They also provide features that encourage attendees to participate in sessions, increase their overall engagement and enjoy the event more.
While this depends largely on the type of event being held as various features support certain aspects of each event. Typically, most events do have the following requirements:
- Content discovery – event info, agendas, exhibitors
- Engagement Features – gamification, polling, Q&A, surveys
- Monetization – lead generation and brand awareness
- Reporting
An event app can have several positive effects on an event. Most frequently the main benefits of having an app include the following:
- Cost savings – reduction in printing needs such as schedules and signage. Additionally, event apps can alleviate staffing for ushers, info desks personnel, mic runners, etc
- Changes and Updates – Events are fluid and things happen. Room changes, speaker cancellations and last-minute changes can be immediately communicated to attendees no matter where they are
- Modern feel to the event – Let’s face it, no one wants to lug around an event guide any more. Going digital is convenient, sustainable, and accessible for your attendees. Plus, they look great and adhere to your desired brand experience
- Creating a digital footprint that can be monitored and managed. Lead generation, attendee satisfaction and attendee behaviors can be collected tracked and managed via an event app
Event apps are created to ensure that attendees have a positive event experience. By taking advantage of the devices already in their pockets, event apps ensure attendees have not only the information they need about the event, but a way to engage directly with it.
Event apps are the “engagement” part of the event experience, usually leveraged during the event. Event management changes radically before during and after the event. Event apps provide the ability to positively affect the attendee experience when the event is going on. An event management platform allows attendees to make choices about the event experience, drive attendee behaviors during the event and collect feedback after the event. Event apps are the key solution for the operational side of events.
Why Cvent



